DIKU - Targeting the JVM
After hours (and oh so much coffee) working my way through hard to pinpoint errors, thrown as a result of incorrectly formatted Java class files, the language now compiles down to Java bytecode.
You can view the source here.
The following shows the compiler in action on our initial sample program:
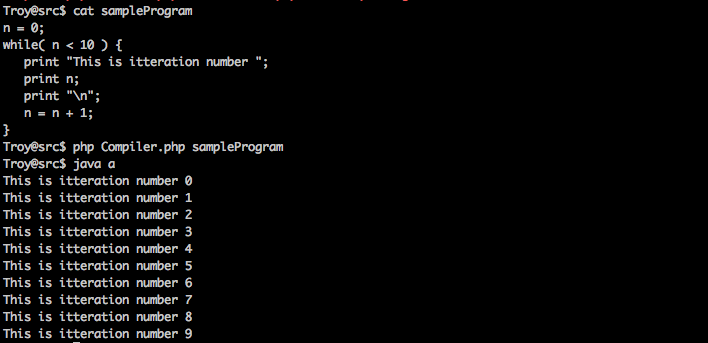
This last step was by far the most frustrating, but also the most rewarding. I’m really glad it’s finished, and working.
There are a lot of magic numbers in the the new Bytecode class, but I feel in this instance, this makes the code slightly more readable. I’ve heavily commented throughout, with the structure of these comments being as close as practicable to those in bytecode generated in the last post.
And as many of the basic Java class features are more or less unchanged for our purposes, there aren’t too many non-trival features in the Bytecode class, the most dificult task being having to keep track of ‘index’ locations in Java’s constant pool data structure as new strings are added.
All of the ‘heavy lifting’ is handled by the Compiler class, with the bytcode simply printing out a series of strings.
Internally, the contents of the output file is stored as a string - with php’s pack() function used to format this string to hexidecimal, before being saved to a file, a.class.
Bytecode uses two helper functions, strToHex() and paddedHex() - the latter converting a decimal integer to hexidecimal, padded to the left by 0s, such that the returned string’s length is a multiple of another integer passes as an argument.
This project could well be extended beyond its current features to create a richer, more capable language - and if you feel so inclined I encourage you to fork the repository, and see what you can come up with.
For me though, whilst we could push this a little further, say to x86, I feel it’s time to move on to the next project.